
Blockchain Intro Series: Replicated Systems
Disclaimer: The content of these research summaries has been written after a year of reading, researching and writing about blockchain technologies and applications. Definitions may vary depending on the paper cited. The summaries provided are subject to further iterations; whereby, the first version relies on my personal understanding of the industry and the technologies. Most of it is based on informal discussions, academic papers, industry whitepapers and primary research. These research summaries may foster from previous research but do not replicate any ideas or content created previously.
Overview
The term ‘replicated system’ generally refers to a collection of parts, for which instance does not only one but instead multiple identical copies exist. It is desirable for the system to keep these copies identical over time to prevent inconsistencies. Thus, if one instance of the system changes, all replicated instances may also be updated; either manually or automatically, depending on the design of the system.
A replicated system may or may not be distributed and vice versa. Also, distribution does not equal decentralisation. In this case, distribution refers to the maintenance of the system across regions and entities. A system may be distributed or replicated but not decentralised. Therefore, a replicated system may have several copies, which are kept in a single place with a single entity having access and update rights. If a central authority is able to make autonomous decisions about the state of the system, then it is not decentralised. For a system to be decentralised decision-making should either be possible by groups or individuals on single instances of the system or as a collective for all instances.
This post will first provide an introduction to different blockchain design elements and terms, then it will analyse specific use cases of replicated/distributed systems, attack vectors, and at last, it will outline different areas of development and outstanding research.
Blockchain Design Elements
Blockchain overview
A blockchain is a type of replicated database. The information stored is divided into data chunks, which are referred to as blocks. Each block may have a coherent data structure depending on the blockchain. All blocks build together a chain that classifies blocks into sequential order. Resulting, somebody viewing the data in the blockchain will be able to tell when certain information has been added. This property allows information to be trackable; i.e. users know exactly when they have been provided with what amount of funds and where those funds derived from.
Depending on the design of the blockchain, users will be able to have insights into the value creation, maintenance and transfer of digital assets; not only within their own account but also of the accounts of other users in the system. Since blockchains are used to keep track of a record of data inputs and outputs, and the state resulting from those, it can be called a ledger. Thus a blockchain may be called a replicated ledger. Again, whether or not the ledger is also decentralised or distributed will depend on its design. You can read further about decentralisation and its limitations here.

Figure 1 An example of the data held within a blockchain. For more information, please read here.
Nodes
Data appended and stored into a blockchain is usually concerned with value creation, maintenance and transfer. This may be expressed in messages, including transactions between different nodes in the system. A node is a user or machine, which keeps track of the data appended to the ledger and the validity of those. Depending on the design of the ledger, the nodes will have to follow various consensus mechanisms. When in agreement on the validity of new transactions, the transactions are inserted into the next block and the block is appended to the existing chain; thus, becomes part of the blockchain.
The high-level process is as follows:
- A user (node) submits a transaction to the blockchain.
- Other nodes will receive the transaction into their transaction pool. The transaction pool is basically the register of transaction that are not yet validated and appended to the ledger.
- To create a new block, transactions are gathered and packed into a new block.
- The new block is appended to the blockchain.
- Any additional blocks are appended to the existing chain.
Note that a transaction is not automatically final once it is submitted to the ledger. Depending on the consensus algorithm, nodes have to wait a certain amount of time until the transaction is deep enough in the chain so it becomes more likely that the chain is used for all future blocks. In contrast, nodes may append blocks on alternative chains. This process may cause forks and alternative chains. To decide which chain to build additional blocks upon, nodes may use the longest chain rule or a weighting mechanism. In case of the longest chain rule, nodes may follow the longest currently existing chain and disregard any chains, which are shorter than the current chain. In contrast, it is also possible to use weighting mechanisms to decide which chain should be built upon. In that case, nodes may build upon a shorter chain, which has higher validity/value than other chains.

Figure 2 Both the Green and the Red chain built upon the Blue chain. Under the longest chain rule, the Green chain will be valid.
Furthermore, we can distinguish between different types of nodes.
Mining/Validator nodes
Mining nodes refer to the nodes that do the work on the blockchain. The work generally entails to gather new transactions from a pool and append those to the ledger through a validation algorithm that requires the node to ‘find the new block’. For more information on this, please refer to my documentation on Consensus Mechanisms. Miners are compensated for their work with transaction fees and block rewards. When a node submits a new transaction to the pool, they have to submit a transaction fee along with it. The transaction fee is a payment for to the miner(s) for submitting their transaction to the blockchain. The mining reward is given out with each newly mined block. Depending on the design of the blockchain, the block rewards are either newly created tokens or existing tokens in circulation.
Consider that it is highly difficult to find a new block. Thus, the energy, funds and time spent on finding the block may not be worth the reward (the cost of finding an additional block may depend on the consensus mechanisms used). In the case of Proof of Work (PoW) mining in Bitcoin, it may take approximately three years for an individual miner to find a block if she/he is not collaborating with other miners. To be more profitable, miners may gather into mining pools. Mining pools allow miners to collaborate, share their resources and ultimately, also their rewards when a miner of the pool discovers the next block. Arguably, mining pools contribute to the centralisation of a replicated ledger. However, it would currently take 4 of the largest mining pools in the Bitcoin blockchain to gain the majority of hashpower in the network. For more information, you may want to read this.
Full nodes
Full nodes are nodes in the network that either operate as miners or still run the entire blockchain to enhance the security of the chain. The more nodes, who run and verify transactions on the blockchain, the more decentralised and secure it will be. All miners are full nodes but not all full nodes are miners. To submit more complex operations to the blockchain, nodes generally have to be full nodes.
Light nodes
In contrast to full nodes, light nodes are not required to verify the entire blockchain and every transaction within. Instead, light nodes mainly receive the blockheader of every block. Light nodes are able to submit generic transactions to the network.
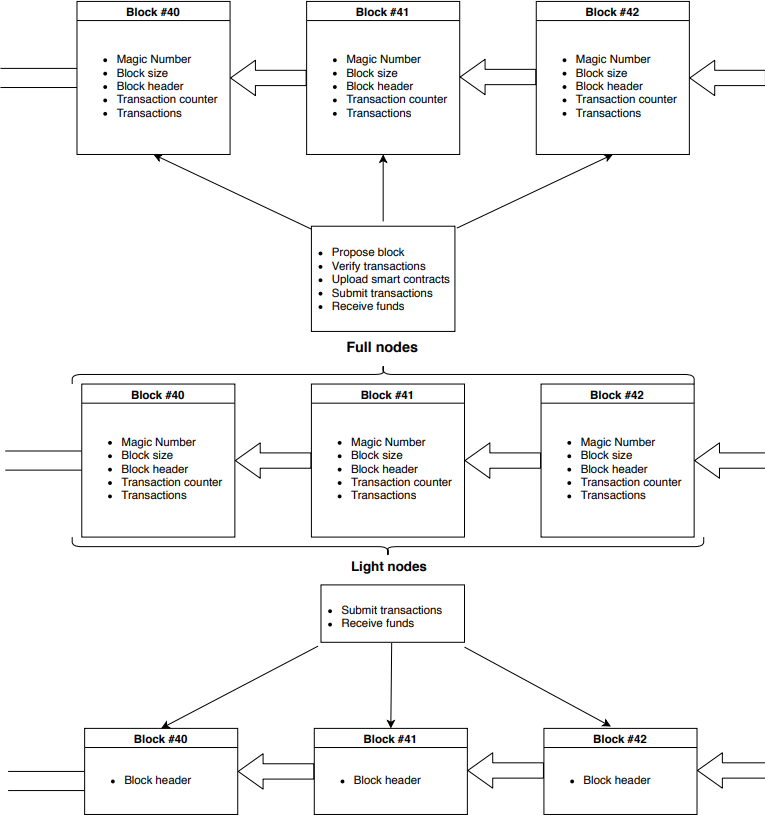
Figure 2 Rough overview on the differences between full and light nodes.
Level of Authority
Generally, we can distinguish between three different types of blockchains; permissioned, consortium and public blockchains. A blockchain has to have certain characteristics to fall into either of these categories. Across blockchains, depending on its design and purpose, nodes may take on different roles with different levels of authority and decision making rights. For more information, please refer to my summary on Consensus Mechanisms.
Public
Generally, public blockchains are accessible to any node. Any node may become a miner, a full or light node and submit, verify and append transactions to the blockchain. Generally, public blockchains are the most decentralised since more players can get involved into the value creation and preservation than in any other type of blockchain. The purpose of public blockchains is to provide open accessibility to allow community driven use cases such as crowdfunding, gaming, etc. Due to its properties, public blockchains are said to be the most secure, transparent and reliable.
Private
Private blockchains may be described as the opposite of public blockchains. Users have to obtain permission to access the blockchain, verify and sometimes even append transactions. The decision making is not done by the users of the blockchain but a central authority that created the chain and defined all interaction mechanisms between nodes. Resulting, this authority may be able to change properties, transactions, etc., on the blockchain without a majority consensus obtained by other nodes in the chain; making the chain not tamper proof and as resistant to attacks as any centralised database. However, in contrast to centralised databases, private blockchains may offer additional transparency features to its users. Therefore, they are highly attractive to use within cross-business operations, whereby each company acts as a node and has the same level of authority, thus, increasing trust between those.
Consortium
A consortium is a permissioned solution for a public blockchain. The chain can generally be accessed and used by any node. However, only assigned nodes will be able to verify transactions, value creation and preservation. Thus, only such nodes are also able to tamper with the information available in the blockchain, retrieve funds from users, and reject community consensus. Resulting, consortium blockchains are more accessible than private blockchains but do not provide the same properties as public blockchains such as tamper resistance, transparency and security.
Users have to be aware of various blockchain implementations to understand and evaluate the value provided by those. For more information, please refer to my post on ‘Blockchain Implication Bias’.
Design Trade-offs
Blockchains face several design trade-offs. Depending on its architecture, value prioritization, level of authority, etc., a blockchain will only be able to achieve at most two of the following: Decentralisation, Security and Scalability. Blockchains prioritise those trade-offs differently to reach different levels of each aspect. For more information please refer to my summary on Consensus Mechanisms and Scalability.
Types of Replicated Systems (Blockchains) & Purpose
Bitcoin
The Bitcoin blockchain is probably the best known blockchain. The design has been published in a whitepaper by an unknown character called ‘Satoshi Nakamoto’ in 2008. To summarise, Bitcoin provides a digital payment system, which aims to eliminate the middleman required in financial transactions such as provided by centralised financial institutions. The blockchain is highly simplistic and used for low-level value transfer. It is a public ledger that operates on the Proof of Work (PoW) algorithm. Any user may access the blockchain and transfer Bitcoins, which are the digital tokens used by Bitcoin. For more information, please refer to my summary on Consensus Mechanisms.
Ethereum
Ethereum is probably the second best known blockchain available. It was built as an improvement to the functionality of the Bitcoin blockchain to cater for more complex use cases. Ethereum does provide a scripting language called Solidity, which allows users to build and deploy smart contracts on the Ethereum Virtual Machine (EVM). Smart contracts are digital scripts that resemble conditions and execute various options, depending on the provided input. Theoretically, Ethereum is Turing complete, meaning that it can execute all kinds of tasks successfully and deterministically. However, computationally intensive transactions are limited by a block size. If Ethereum would allow for various computations, the type of machines that may be able to execute those would be limited. Resulting, the network limits the type of operations that can be executed in smart contracts.
Transactions & Wallets in Bitcoin vs. Ethereum
Balance based
Generally, funds, such as coins or tokens, are stored in user wallets. Note that a wallet does not reference a place that keeps all funds. Instead a wallet references the access to the funds in form of an address. The cryptographic mechanisms of wallets are detailed further in my summary on Cryptography. While Ethereum uses a balance based model, Bitcoin is based on an UTXO based model. The balance based model operates theoretically similar to a bank account. The user has a balance which shows the current funds and the value of those available in her/his wallet. In case the user transfers funds to another wallet, the value of those is simply reduced from her/his overall balance. In case funds are added to the wallet, the balance is updated = previous balance + additional funds received.
UTXO based
In contrast, Bitcoin uses an UTXO (unspent transaction output) based model which is a bit more tricky. It can be compared to a physical wallet. A user has several coins and bills. In case the user wants to pay their $40 grocery shopping, they may give the cashier a $50 bill. The $50 bill can hardly be split up into separate chunks. Thus, the user will have to give the entire bill and receive a $10 bill in return. Similarly, the user may provide two $20 bills. However, while there is no $40 bill in real life, which the user can make use of, in the case of an UTXO model, the user may merge two $20 bills -- or outputs – into one input.
Obviously, in the case of Bitcoin, the user does not use USD bills but instead Bitcoin which have a different value assigned to them. Each coin that is submitted, for example, from user A to user B, is called the input. Alice submits as input 0.01 Bitcoin to Bob. When the 0.01 Bitcoin reach Bob, it is his output. Note that Bob might have additional outputs in his account but those remain separate from the 0.01 Bitcoin that he just received from Alice. However, he could merge separate outputs together. This way, they would be the input into a new output.
Comparison
Both the account and the UTXO based model have different advantages and disadvantages. While the balance based model has limited use cases, it is really easy to grasp for users; thus, limiting the barriers for users. In comparison, an advantage for the UTXO based model is that it allows users to separate their total balance into different outputs. A disadvantage of this is that Bitcoin has to keep track, not only of the overall balance of each user, but of each individual output, which may make the blockchain too big over time that users are unable to run the entire blockchain on a normal machine. Also, some outputs are so small that they cannot be used for any transaction nor to be combined with other outputs since transaction fees may be higher than the output itself. Those outputs are called dust and just lie around on the blockchain without being touched. You can read more on this in the following paper.
Attack Vector
The general perception is that public blockchains are one of the most secure databases that can be used to keep track of value creation, transfer and preservation. However, even public blockchains are subject to various attacks. The likelihood of different attacks and defense mechanisms in the protocol design may largely depend on the consensus mechanisms in place. This section merely provides an overview.
Sybil attacks
In the case of a Sybil attack, a node may have various identities on the ledger. Ledgers generally store identities in the form of wallet addresses. However, one user may have multiple wallet addresses. Those cannot be reliable attributed to the same user. Thus, the user may operate multiple identities on the network. In most cases, this is quite harmless since the user is unable to do much else other than operating those identities.
In contrast, if a malicious node deliberately aims to replicate the identity or gain access to the identity of reliable nodes in the network to fool other nodes in trusting her/him, then this becomes an attack on the network. In some cases a sybil attack may be coupled with an eclipse attack to be more effective.
Centralised systems aim to prevent sybil attacks by requiring a unique authorisation that cannot be replicated across accounts, such as a passport, or an IP address. In contrast, blockchains require nodes to provide some form of resources to proof their credibility. Depending on the consensus mechanisms in place, this resource may be based on the funds owned or the computational power provided by an address. The more resources that an individual user can provide, the more reliable she/he may be in the system. The idea is that each user will have a finite amount of resources available to gain credibility within the network. Distributing one’s resources across multiple addresses will only dilute its impact.
Eclipse attacks
An eclipse attack is similar to a sybil attack. The malicious node will pick a node (usually a node with a high amount of funds) and replicate its view on the network. Thus, if this is done right, the attacked node will not realise that it is being attacked since its view on the network remains the same. Once the node transfers funds to another node in the network, they will not be received by the actual peer in the network but rather the malicious actor.
To understand how eclipse work it is important to know how nodes in a network connect to peers, i.e. other nodes in the network, and communicate with each other. Generally, nodes connect over a distributed hash table, which stores the list of all nodes, but no single node is connected and has to know about all other nodes in the network. Instead, in the case of Bitcoin, nodes connect to 8 other nodes and in the case of Ethereum to 13 other nodes. The nodes a user (also node) is connected to will change over time. When appending a new transaction to the network, a node will broadcast it to its 13 peers (in the case of Ethereum). Those peers will each broadcast it again to their peers and so on until all nodes in the network have heard of the transaction.
Selfish mining attack
Generally, miners aim to find the next block just before anyone else does to receive the block rewards. With each newly published block comes a type of randomness. This randomness may be used for games, voting, and any other use cases that should provide unforeseeable results. Thus, this miner knows the randomness of the next block before anyone else. If the randomness is not in her/his favour, she/he might choose to withhold the block and not to publish it, waiting for another miner to find the next block and publish it with a different randomness value attached.
While this attack is not necessarily harmful to the funds stored on the blockchain, it may tamper with the state of the blockchain and the funds of individual users. The only way to prevent this is to provide miners with enough incentives not to behave maliciously.
51% Attacks
Like mentioned earlier, it is possible for nodes to obtain the majority of hashpower/mining power in the network; even though this is generally very difficult in public blockchains. In the case of private blockchains, this may be a given characteristic. Public blockchains aim to prevent individuals or a group of players to reach the majority consensus. In case a miner or mining pool reaches over 51% of hashpower in the network, they can tamper with the state of the network in whatever way they feel like. This attack is mainly prevented through mechanism design and the level of decentralisation/distribution of the network. Every attack on the network will impact, in one form or the other, the trustworthiness of the network and the value transferred within. Resulting, the price of the token may crush if the network is under attack. Therefore, it is assumed that miners have little value to gain out of such an attack besides the destruction of the network.
Distributed Denial of Service (DDoS) attack
Overall, a DDoS attack aims to compromise the availability and consistency of data and services on a network by completely overflooding the system with service requests. In the case of centralised databases this is highly fatal if an attack is launched on sensitive information such as the records of medical patients. Similarly, financial institutions should be available 24/7. A DDoS attack on a bank would cause businesses and individuals not only to lose high operational costs but also the loss of personal funds. While banks may allow the access of client records any time, services are only available during working hours. In contrast, replicated ledgers such as blockchains aim to improve upon the availability and trustworthiness of existing institutions by empowering users. However, decentralised applications may still be affected by large payers and applications, which accidentally or intentionally cloak the network.
Replay attacks
Replay attacks reference the malicious or replicated information transfer on replicated ledgers. It is a form of a ‘man-in-the-middle attack’ that allows the attacker to replicate data or data transmission into a different context than originally intended. This form of attack is more likely in the case of a system update, a fork, as well as sharded ledgers. (For more information please refer to the other summaries on Scalability and Governance.) In the example of a system update, Alice may wish to transfer funds to Bob. While Bob already updated the ledger, Alice did not. Therefore, the input of the transaction will be on Alice’s chain and the output on Bob’s version of the chain. An attacker who is observing Alice’s transaction could potentially replicate the exact same transaction on Bob’s chain but retrieve the funds for himself. To prevent this, it has been proposed to submit dummy messages to the destination chain (Bob’s chain), which replicate Alice’s input. To read further into this issue, here is a paper on replay attacks and the potential solution mentioned above.
Use Cases
The sections above aim to provide a high level overview on replicated ledgers, how blockchains classify as such, the different design variations of blockchains, the most popular types of ledgers and potential attack vectors. The theory might sounds highly exciting and various implementations can be imagined, such as a decentralised Uber, empowering the users to obtain full control over their own finances, independent economies, etc. This leaves us with the question about the use cases currently in existence and what obstacles we have to overcome to expand on those.
Use cases
- Decentralised Gaming
- Social networks
- Asset management
- Financial services
- E-voting
- Notary & Law
- Integrated verification
- Insurance
- Enhancing privacy and anonymity
Remaining obstacles
- Solving potential implementations of decentralised identity registration and management to provide for more advanced use cases, such as voting.
- Providing decentralised governance processes that are inclusive, available, accessible, transparent and fairer than current governance structures.
- Preventing the ruling of the rich in case of most consensus mechanisms.
- Successfully scaling blockchains without compromising on security.
- Providing secure interoperability mechanisms between independent blockchains.
- Enhance usability of current and future blockchain applications.
Main Points
- The term ‘replicated system’ generally refers to a collection of parts, which instance does not only exist at one place but instead allows for multiple identical copies.
- A blockchain is a type of replicated database. The information stored are divided into data chunks, which are referred to as blocks. Each block may have a coherent data structure depending on the blockchain. All blocks build together a chain that classifies blocks into sequential order.
- A node is a user or machine, which keeps track of the data appended to the ledger and the validity of those.
- Mining nodes refer to the nodes that do the work on the blockchain. The work generally entails to gather new transactions from a pool and append those to the ledger through a validation algorithm that requires the node to find the hash of the new block.
- Full nodes are nodes in the network that either operate as miners or still run the entire blockchain to enhance the security of the chain.
- We can distinguish between three different types of blockchains; permissioned, consortium and public blockchains.
- Private blockchains may be described as the opposite of public blockchains. Users have to obtain permission to access the blockchain, verify and sometimes even append transactions.
- Blockchains face several design trade-offs. Depending on its architecture, value prioritisation, level of authority, etc., a blockchain will only be able to achieve at most two of the following: Decentralisation, Security and Scalability.
