
If you have been using Kubernetes for some time now, you likely have heard of Kubernetes operators.
This short article provides an overview of Kubernetes operators, what they are, how they work, and when and why to use them.
Why do you need an operator?
The power of Kubernetes lies in the Kube API — basically, the Kubernetes component that allows you to communicate through kubectl with the Kubernetes cluster, schedule, and modify workloads. Through Kubernetes Custom Resource Definitions, you can extend the API and build your own custom Kubernetes resources. Operators do precisely that to deploy and run complex processes in your cluster.
When interacting with Kubernetes resources, you might have to perform many manual tasks. This can become highly problematic in large-scale environments. We are just humans, and humans love making lots of errors.
Operators help us to automate processes in our infrastructure and our application stack. There are operators for all kinds of tasks; some deploy applications, some track the state of your cluster, and others perform scans on an ongoing basis. The list goes on.
What is an operator?
Kubernetes works based on controllers — these controllers perform continuous checks or similar. "An operator is a client of the Kubernetes API that acts as a controller for a Custom Resource", such as the resources described above. (Source)
You would deploy an operator like another set of custom resource definitions (CRDs) to your cluster.
The diagram below shows a basic Kubernetes cluster with an operator installed:
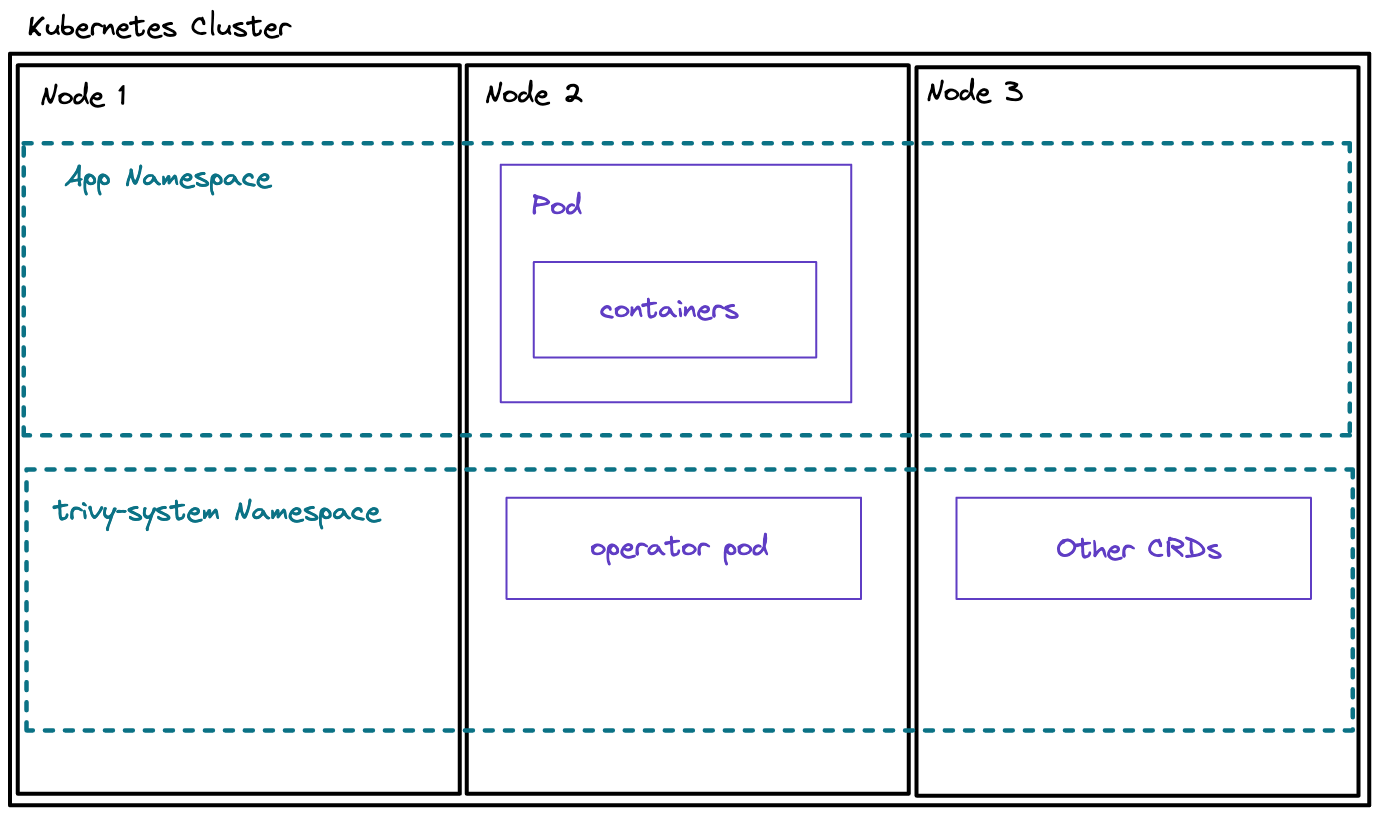
Alternatively, you can try out installing an operator. I have looked at several different operators in my previous videos. A popular example is using GitOps tools to control your deployment processes, as explained in the following videos:
- Implementing GitOps best practices with Crossplane and ArgoCD
- Kubernetes security scanning with Trivy CLI and Trivy Operator
- Full GitOps Tutorial: Getting started with Flux CD
At AquaSecurity, we also use an operator to perform security scans within your cluster. The Trivy Operator can be installed through the following Helm commands:
helm repo add aqua <https://aquasecurity.github.io/helm-charts/>
helm repo update
helm install trivy-operator aqua/trivy-operator \\
--namespace trivy-system \\
--create-namespace \\
--set="trivy.ignoreUnfixed=true" \\
--version 0.1.3
You will then find the operator pod running inside of your trivy-system namespace:
❯ kubectl get all -n trivy-system
NAME READY STATUS RESTARTS AGE
pod/trivy-operator-767b94b97f-4hm69 1/1 Running 0 46h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/trivy-operator ClusterIP None <none> 80/TCP 46h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/trivy-operator 1/1 1 1 46h
NAME DESIRED CURRENT READY AGE
replicaset.apps/trivy-operator-767b94b97f 1 1 1 46hNow it will run in-cluster Vulnerability Scans whenever it detects a new workload with a container image that it has not yet scanned. If you deploy an application, you can then view the Vulnerability Reports and the Config-Audit-Reports:
❯ kubectl get vulnerabilityreports
NAME REPOSITORY TAG SCANNER AGE
replicaset-react-application-7b85598f95-react-application anaisurlichs/react-example-app 8.0.0 Trivy 2m38s
- You could then describe the resource to read the vulnerabilities of your deployment or use our Lens extension to view vulnerabilities in a neat way as shown below in the tweet.
Trivy Operator v0.1.3 Released !!
— Chen Keinan (@ChenKeinan) July 13, 2022
Now it is easy to scan and protect your k8s cluster
- RBAC Assessment
- Exposed secrets
- Prometheus metrics for the finding
And all together with cool trivy-operator-lens-extension
Check it out : https://t.co/1Y9gbKTrm3 pic.twitter.com/87CWMGERoe
In this case, the Trivy operator performs multiple tasks:
- Monitoring your cluster
- Running Scans whenever a new workload is detected
Continuous monitoring of your cluster resources or specific workloads is one of many operators' key tasks.
So how far can you take operators?
Last year, my ex-manager Alex Jones and I spoke at KubeCon about how we managed the Civo infrastructure through operators.
You can find the entire talk here:
Basically, we had to manage several large-scale regional clusters — these regional clusters were responsible for spinning up tenant clusters on their compute nodes within. Below is one of the diagrams from the presentation:
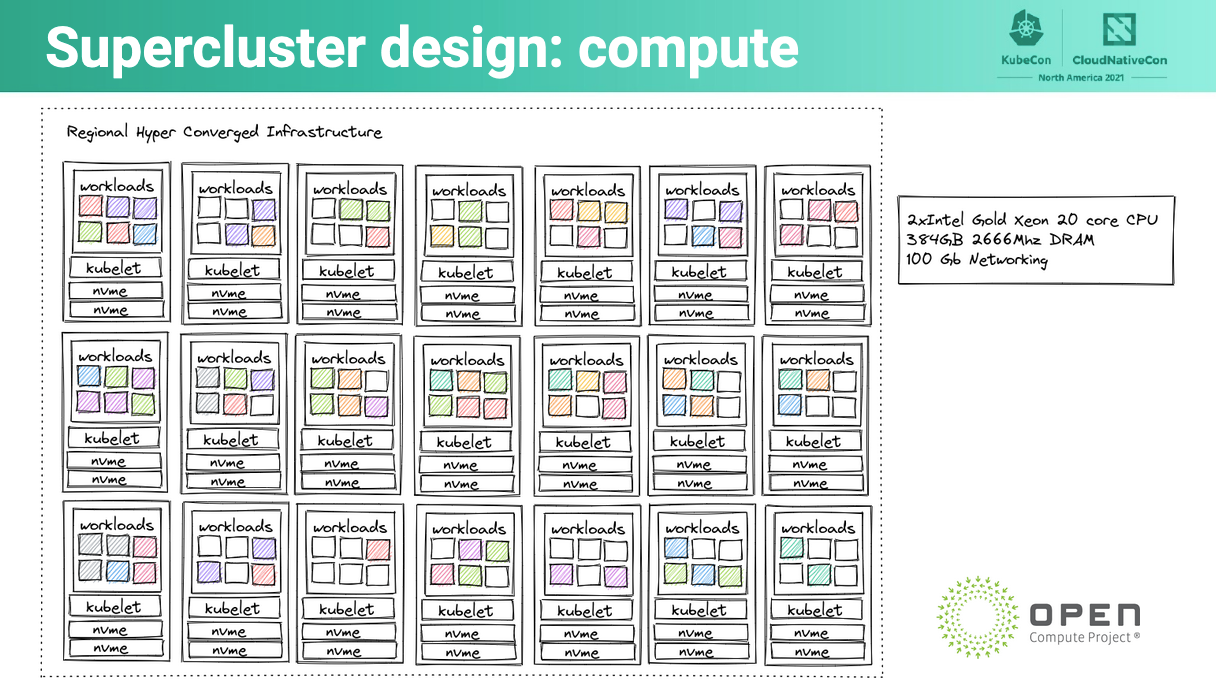
This diagram represents one of our regional super-clusters.
We used operators to control the processes to spin-up tenant clusters, among others. This leads us to the next section, how do you build operators?
Building an Operator
Operators come in different formats. Depending on the type of operator you want to build, there are different templates and similar that you can use.
For instance, we’ve built a Crossplane provider, which is more or less an operator, with the tools provided by Crossplane.
Alternatively, you could use the Operator SDK which is used across a variety of projects. Also, there are several smaller templates. These templates show you how to develop an operator in Go (for example). However, be careful in choosing templates. Operators usually get lots of access to your cluster resources. Thus, choosing a robust template is the first step in not exposing your cluster to unnecessary security risks.
This leads us to our next section…
How secure are operators?
Kevin Ward from ControlPlane gave this brilliant talk at KubeCon: Tweezering Kubernetes Resources: Operating on Operators
In the talk, they introduced the following tool:
 controlplaneio
controlplaneioAlso, I highly recommend watching the talk. This tool allows you to check your operator for security issues.
Again, you want to ensure that you follow security best practices when choosing, using or even developing an operator, such as the least-privileges model and similar.
What is next?
I hope this blog post gave you an excellent overview of Kubernetes operators. If you would like to have more information, I highly suggest reading this blog post by Ivan Velichko:
 Ivan Velichko
Ivan Velichko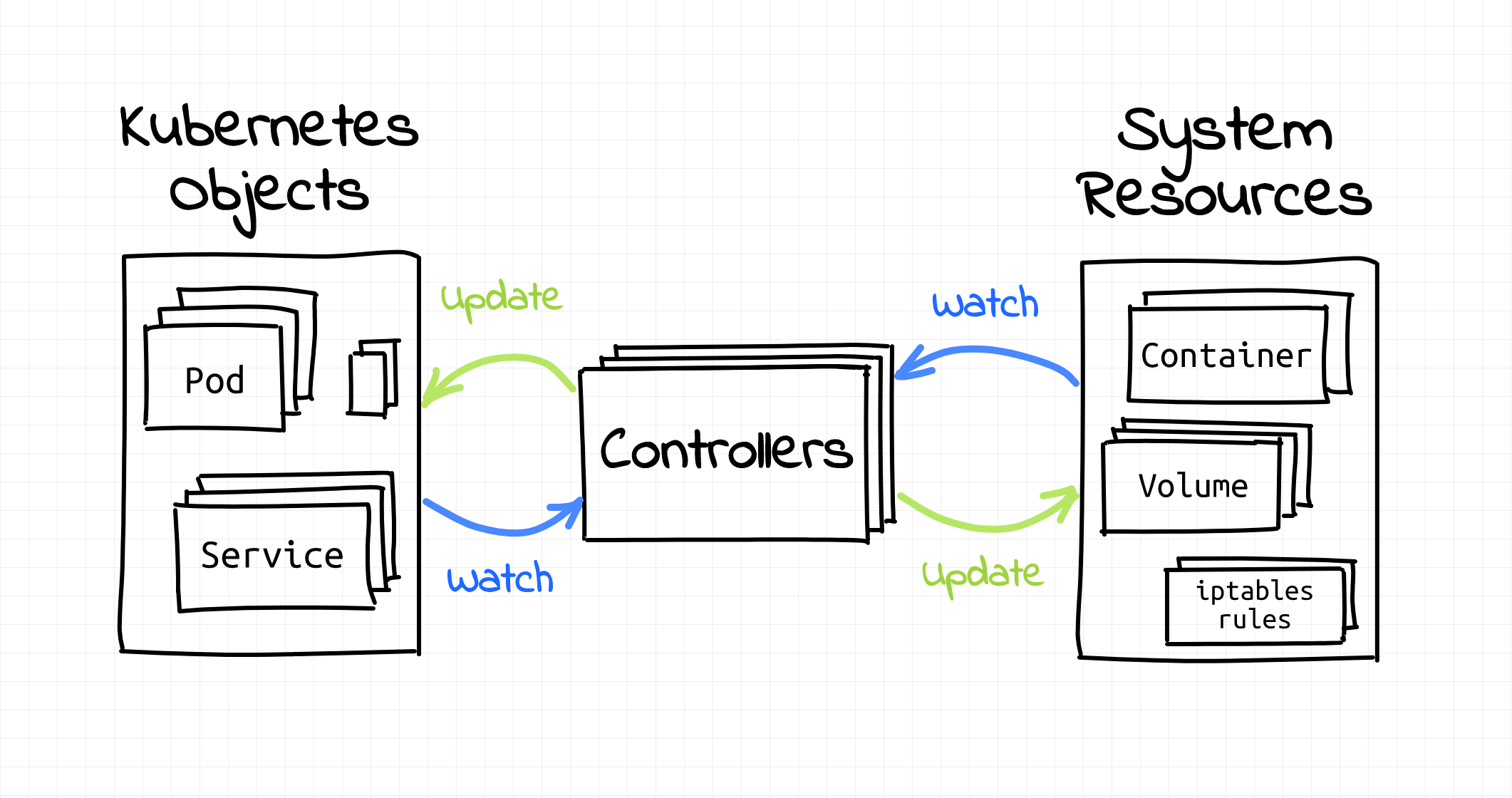
Also, I would highly appreciate it if you could give my YouTube video a like, subscribe to my channel or even share my content ♥