
Security Scanners — What are they and how to use them

Throughout the past six months, I gave lots of different presentations on using security scanners, and specifically on getting started with Trivy. Trivy is our open source security scanner at Aqua. You can find the GitHub repository here:
 aquasecurity
aquasecurityAmong many other questions, I realised that there is confusion on the following:
- When you should get started with security scanners
- Why you should get started with security scanning
- Who is responsible for security in your team
- Which scanners to choose and why
In this blog post, I will try to clarify these, among others.
If you prefer to listen to my voice instead of reading, this video provides the same content:
Moving to containers and cloud-native applications
Before you even think about deploying your workloads to a Kubernetes cluster, you should get started with containerisation.
Containerization is the packaging of software code with all its necessary components like libraries, frameworks, and other dependencies so that they are isolated in their own "container." Source
So you want to learn about defining and building container images first, before you learn how to use container orchestration systems such as Kubernetes.
The thing is, while many people will get started learning about containers, they will start to learn about security at a much later stage; often when they are already working on Kubernetes production environments. This is a huge mistake — let me tell you why.
Previous CVEs “demonstrate that key components in the toolchain and the stack, if vulnerable, can affect a containerized application. It’s not just the container code itself, or the container engine that may affect your security posture, but many elements across the stack.” Source
Meaning, that vulnerabilities of your container image can be exploited across other elements of your security stack — someone does not need to have direct access to your running container images. Similarly, vulnerabilities in your container images can be used to compromise other elements across your infrastructure and deployments.
Below are some stats listed, but ultimately, when you start learning about container images, you want to learn about best practices and ways to enhance security.
Security Scanner
What is a security scanner in the first place? A security scanner allows you to scan engineering resources for vulnerabilities and misconfiguration. Some security scanners also allow you to scan other resources such as Secrets, Licenses and many more. A security scanner is responsible for checking your resources against a database of vulnerabilities or best practices. Let’s start with the example of vulnerabilities.
Vulnerability Scanning
Software is dependent on software packages. For instance, container images are composed of several different packages. We can list the packages in a container image with the following command:
docker exec -i <container_id_1> apk info -vv | sort
docker exec -i node-example apk info -vv | sort
Note: make sure that a container e.g. a node container is running.
These packages naturally become updated over time; for instance, people will find vulnerabilities in the code, add new features or similar.
Thus, once the packages a container image depends on are updated, the container image will also have to be updated eventually.
You expose your application stack to unnecessary vulnerabilities if you keep using older versions.
Why security scanners are so important
The whole idea about moving to containers and cloud native technologies that run on Kubernetes is to be able to update your application as well as the versions in your dependencies more frequently.
Things are moving a little bit faster in this space. If we can deploy updates to our application several times per day, we have to check our deployments continuously for vulnerabilities. In the past, when teams deployed once a month or every other month, they could schedule a few days at the end of the sprint to make updates to their deployments. However, this paradigm does not apply anymore. If you schedule two days a month to check for vulnerabilities, the other 28 days vulnerabilities can be exploited.
We often treat security reactively rather than proactively. Security Scanners enable you to check for updates with every deployment proactively. You don’t have to wait for vulnerabilities to be disclosed or even for them to have been exploited to make your application more robust.
Who is responsible for running vulnerability scans?
You will want to run vulnerability scans at different stages of your deployment lifecycle. The graphic below demonstrates different vulnerability scans that can be performed on different resources throughout your deployment lifecycle:
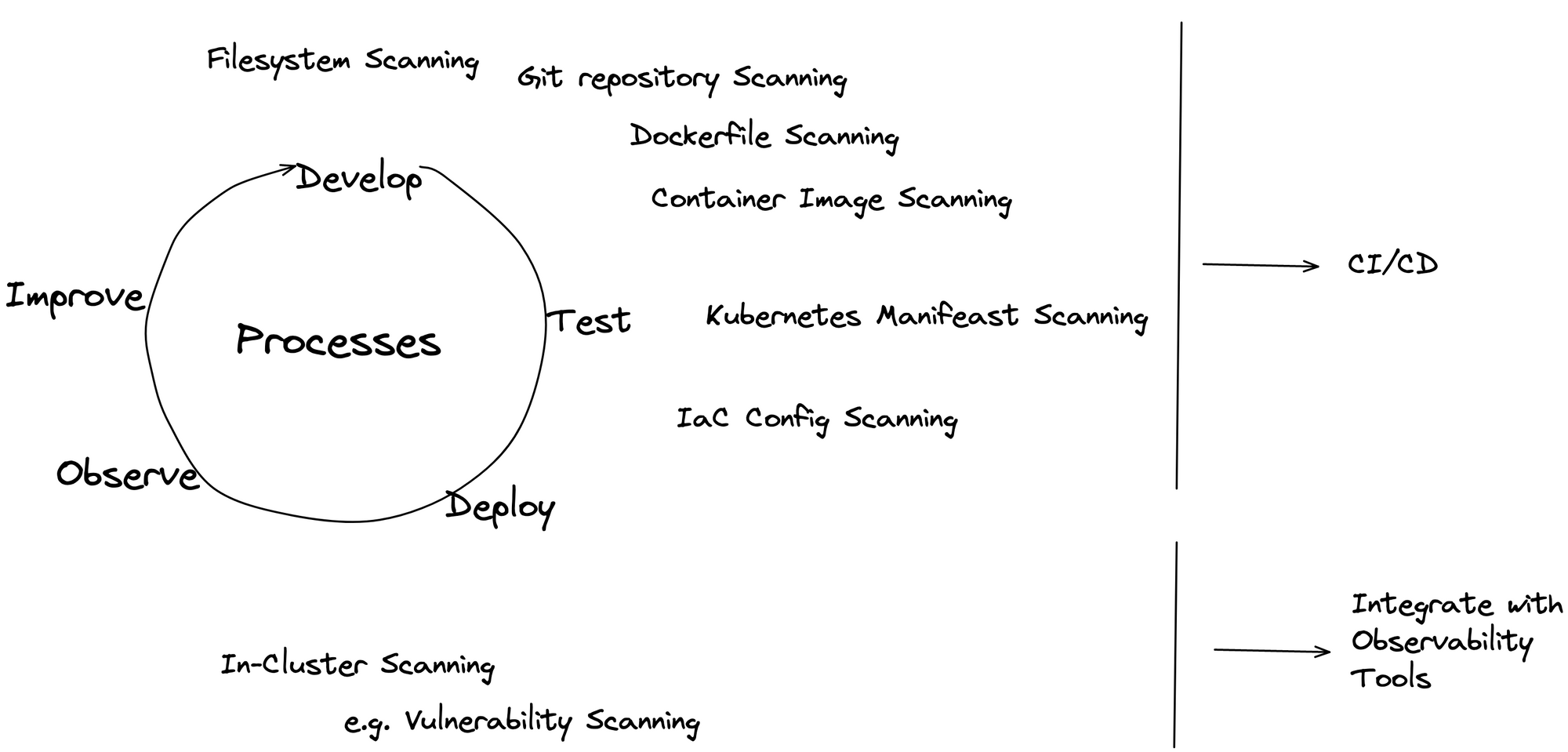
At the beginning of your development process, the Engineers will be able to scan resources such as
- libraries and third-party packages used in your code
- local and remote Git repositories
- local filesystems
- container images used in your application
and more.
These scans would happen by the engineers on their local machines.
Once you enter the testing and deployment stage, you want to integrate security scanning into your CI/CD pipeline. At this point, the responsibilities would shift from the individual engineers to the DevOps or SRE team. Note that this depends highly on the structure of your team, the size and their responsibilities.
Lastly, you want to implement security scanning on your running workloads. It happens a lot that containers and similar are deployed for debugging purposes. Thus, you would also want to implement security scanning on your running workloads. This would the responsibility of those working with and maintaining running workloads.
Vulnerability Scanning should be a shared responsibility
We are talking a lot about shifting left and empowering engineers. However, this often boils down to asking our engineers to perform yet another task. This is often done with the deployment resources, whereby engineers are asked to build their deployment resources. This makes sense since deployment is part of running the app and a crucial step. However, an app can run without security scanning. Thus, security scanning is often not done proactively if it is just yet another thing that engineers have to think about.
Misconfiguration Scanning
Misconfiguration Scans are a bit different to vulnerability scans. Misconfiguration scans are related to your deployment resources, anything that defines how, where and with what your workloads are supposed to run.
In the case of Kubernetes, we often end up writing hundreds of lines of YAML manifests, terraform IaC configuration files or similar. We likely configure something incorrectly in those files. Misconfiguration scans will compare our configuration with best practices and the configuration that would be expected. In addition to telling you what part of your configurations are misconfigured, the many misconfiguration scanners will also show you what you can implement or change for better configurations.
Misconfiguration scans can expose our application stack to unnecessary security risks. Below are a few examples of configuration scans exposing sensitive information and other data. If companies make these kinds of mistakes, so will individual people.
Examples
Razer
Elasticsearch misconfigured: Elasticsearch cloud cluster that exposed a segment of Razer’s infrastructure to the public internet, for anyone to see
https://threatpost.com/razer-gaming-fans-data-leak/159147/threatpost
Albert Einstein (Hospital)
An unknown hospital employee uploaded a spreadsheet with usernames, passwords, and access keys to sensitive government systems
Exposed Data: patient names, addresses, ID information
Dating Apps
A misconfigured AWS S3 bucket containing 845GB of private dating app records
Exposed Data: photos, many of a graphic, sexual nature; private chats and details of financial transactions; audio recordings; and limited personally identifiable information
https://www.theregister.com/2020/06/16/dating_apps_aws_s3_leak/
You can find lots more exposures in this list: https://github.com/rapid7/data/blob/master/2021-cloud-misconfigurations/2021-cloud-misconfigurations.csv
Choosing a Security Scanner
I could and probably should write an entire blog post about this, but the section below is a start.
Security Scanners differ in several aspects. Which security scanner you should choose depends on a variety of aspects. Some of these are listed below:
- The size of your team — are you an individual contributor, or do you work in a large team with shared responsibilities? You could use different security scanners for different parts of your application stack and development lifecycle. The problem is that this will require you to learn different tools.
- The resources available — Using security scanners requires some training. The question is then whether you or your team can provide the time for it. The training includes learning how to use the tool effectively in your existing infrastructure.
- The goals of the team and management – Especially in larger teams, it can happen that the goals of the management and person deploying and using the security scanner are not aligned. You must be clear about why your team wants to use a security scanner in the first place.
- Your existing security stack – more mature open source applications have more integrations, extensions and plug-ins available with other tools. Especially in teams without the know-how to build your own solutions, the bandwidth or similar resources, you want to use a security scanner that has a more mature ecosystem.
I will write a more comprehensive blog post on this.
What’s next?
I hope you enjoyed this little overview & me sharing some of the insights I started communicating at the previous events.
It would mean a lot to me if you could like the YouTube video, subscribe to my youtube channel or even share this blog or the video on your own social media.
If you have any questions, please comment on the YouTube video as well.
Have a great day! 🌻



