The lifecycle of a Vulnerability

Ever since I started using security scanners, I wondered: What is the process for identifying security issues, for instance, vulnerabilities? Specifically, what does the process look like of a new vulnerability being discovered until I, the end user of a library that contains this vulnerability, become notified and can access a patch?
It is likely one of those things that security professionals who are working in the field know without spending a second thought on it.
In this blog post, I will do my best to detail the process based on how I understand it. I will likely update the blog post as I receive feedback.

What are Vulnerabilities in the first place?
A Vulnerability is a flaw, glitch or weakness in the system that an attacker can exploit. (Source) Vulnerabilities can be introduced into an application stack through software or human errors.
Types of Vulnerabilities
The National Cybersecurity Centre distinguishes between four different types of vulnerabilities:
- Flaws: An unintended functionality. Flaws might be introduced into the application stack due to poor design choices. This is one of the most common vulnerabilities.
- Zero-Day-Vulnerabilities: Commonly, a vulnerability is only disclosed once the vendor who discovered it in their software has had the time to create a patch. This way, users can quickly upgrade their system to avoid exposure to attackers exploiting the vulnerability. However, what happens if a vulnerability is disclosed/discovered before there is a fix available? Users must do their best to remove vulnerable packages while vendors aim to release a patch. In those cases, the attackers will try to attack as many systems as possible.
- Feature: New features often add new vulnerabilities to a system. These vulnerabilities take time to identify and patch. Sometimes, vulnerabilities will be exploited for decades as features and code are reused across applications.
- Use error: The vendors who provide software, applications and related components might do their best to reduce the number of vulnerabilities in the code. However, users often enable vulnerable features, add-ons or similar integrations. Aqua Security gave a talk at Black Hat Asia that detailed how easy it is to publish vulnerable extensions on the VS Code Marketplace.
Different Types of Vulnerability Databases
As with most things, to store, track and share information, we need a database. In the case of vulnerabilities, different Vulnerability Databases have been created. These might either be vendor-specific or provided and maintained by independent entities. This section provides an overview of the different database types.
NIST – Stands for the National Institute of Standards and Technology, which is responsible for the National Vulnerability Database (NVD) that reports on CVEs. The US government maintains the NVD.
Mitre – This is the organisation whose responsibility is to review all reported Vulnerabilities in a CVE database. Mitre was set up in 1999. Many other databases take the information provided and build upon it further.
Open Source Vulnerability Database (OSVDB) – Provides an aggregation of publicly disclosed Vulnerabilities. It was founded in 2002 and launched in 2004.
Note that different countries have their vulnerability databases. Examples are the Chinese National Vulnerability Database and Russia's Data Security Threats Database.
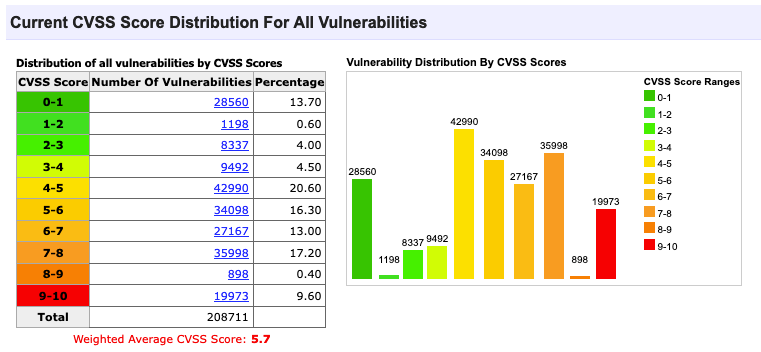
A lot of these databases contain thousands of vulnerabilities. Most organisations don't have the internal resources, time and expertise to review security issues such as vulnerabilities individually. Thus, the databases indicate the severity of the vulnerability. The severity of a vulnerability can be translated into the urgency of fixing the vulnerability.
You can look up CVEs under the following link: https://www.cvedetails.com/
The following abstract is taken from Wikipedia:
The Lifecycle of a Vulnerability
Creating new Vulnerabilities
(No, in this section, I am not going to "teach you" how to create vulnerabilities. However, if you are curious, there are lots of sites that provide bug bounties for identifying new vulnerabilities.)
Where do Vulnerabilities come from in the first place?
The first interaction that most of us will have with a vulnerability is when we use a security scanner, scan our container image, and find a list of 500+ vulnerabilities in our packages. However, I want to take several steps backwards and look at the entire process of how the vulnerability is found and classified, all the way up to the security scanner identifying the vulnerability, which is my source code.
What does a CVE consist of?
Every CVE has
- A Unique Identifier, an ID that includes the year the vulnerability was researched, followed by a unique ID.
- Reference information with further details on patches, recommendations and additional comments for developers.
- A description of the vulnerability
Who is reporting CVEs?
Pretty much anyone can report a vulnerability. Most vendors have a security advisory that notifies users and customers of newly identified vulnerabilities. Once a new vulnerability is identified, it can be reported to the advisory. A vulnerability might be determined by
- a customer
- an employee at the company
- a whitehat hacker
- an option would also be to identify an attack that leads to the discovery of the vulnerability.
Once a vendor receives a report on a new vulnerability, they have 30 to 90 days to disclose it to the public. This gives them enough time to provide a patch, upgrade or similar that fixes the vulnerability.
Where can you find new CVEs?
Vendors would usually access the National Vulnerability Database to decide whether newly disclosed vulnerabilities affect any of the company's stack. However, end users would usually not look at the NVD directly. Instead, end-users scan their application stack and other resources for vulnerabilities using a security scanner.
The vulnerability scanner does the heavy lifting of accessing and filtering the vulnerabilities behind the scenes. For instance, Trivy collected information both from the NVD and vendor-specific databases. It then combines the information accessed in the Trivy DB.
Security Scanning Process
A security scanner will access information from different security advisories and consolidate the information in one database. In the case of Trivy, this database is the Trivy Vulnerability Database. The CLI tool used to scan container images will pull the database locally.
The process looks similar to this:
- The user will trigger a scan of a resources, such as a container image
- Trivy will check how long it has been since the database has last been updated. If more than 6h have passed, Trivy will download the Trivy database again.
- Trivy will try to find all of the libraries and dependencies used in the different layers of the container image.
- Once Trivy has a list of packages and libraries used in the container image, it will check its database to see whether any known vulnerabilities for a package version match the installed package in the container image.
- Based on its comparison, Trivy will display a scan report.
- There is a lot more work going on behind the scenes to classify vulnerabilities
Report
The following tutorial showcases how I identify new vulnerabilities and update the container base image:
Common questions
Why don't we create a new vulnerability Database?
I looked at that topic and research in the field in one of my previous newsletters.
Will update this section in the future.
Summary
I hope the information shared in this short blog post were useful and helped you, the reader, to understand CVEs a little better.
If you enjoy my content, I would highly appreciate a like on my YouTube video or even if you could share my content on your own social media.
Toodles,
Anais
Additional Resources
- Trivy GitHub: https://github.com/aquasecurity/trivy
- Install Trivy: https://aquasecurity.github.io/trivy/v0.49/getting-started/installation/
- Filter vulnerabilities Documentation: https://aquasecurity.github.io/trivy/v0.49/docs/configuration/filtering/
- Filter Vulnerabilities Tutorial: https://www.youtube.com/@AquaSecOSS/search?query=filtering
- The Aqua Security Open Source Channel: https://www.youtube.com/@AquaSecOSS
- Example application used: https://github.com/Cloud-Native-Security/website